初歩中の操作ですが、pythonのpandas操作でCSVを読み込んだ時に、いらないヘッダー(行)やカラム名を変更したい時に操作を記録しておきます。

今回私が使用したCSVファイルを完全再現したいなら、日本銀行の為替時系列データを1970年から「データ表示」してダウンロードしてくれれば再現可能です。
まずはpandasでCSVを読み込む
import pandas as pd
pd.read_csv('XXX.csv',encoding'cp932')
読み込みたいcsvのファイル名をXXXの箇所に入れてpythonの操作をしてください。
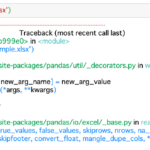
実行結果はこんな感じ

このデータを見てみると、2行目で扱われているデータが不適切だし、各データカラム名が日本語長くて非常に見辛くなっています。
上記を鑑みてpandasで「ヘッダーとして使用する行番号の指定」「カラムの名前指定」「インデックスとして使用する列番号の指定」を操作します。
pandasのデータを見やすくするために、下記の操作を実行します。
import pandas as pd
pd.read_csv('exchange.csv',encoding='cp932',header=1,names=['date','USD','rate'],index_col=0,parse_dates=True)
read_csv()関数に指定を加える事で実行結果は下記のように読みやすくなります。
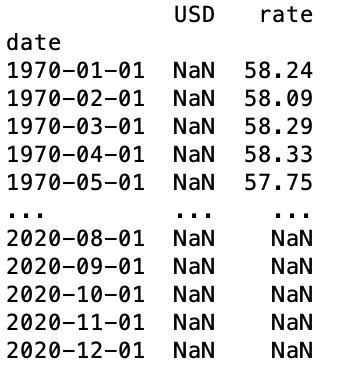
このようにread_csv()関数の指定をしっかりする事で見やすく整形する事ができますとさ。
read_csv()関数で指定できる代表的な引数はこちら
read_csv()関数で指定できる代表的な引数
| キーワード引数 | 内容 |
|---|---|
| encoding | ファイルのエンコーディングの指定 |
| header | ヘッダーとして使用する行番号の指定。Noneを指定すると先頭行から全てデータとしてみなされる。 |
| names | カラム(列)の名前の指定 |
| index_col | インデックスとして使用する列番号(0からが始まり) |
| parse_dates | Trueにすると、インデックス使用した列に対して日時フォーマットにするように試みられる |
| na_values | デフォルトの値に追加でNaNとみなす文字列のリスト |
この操作を知っていれば、わざわざ元のCSVファイルを修正する必要はありません。しっかり覚えておきましょう。
その他のread_csv()関数の扱いを知りたい方は下記を参考にしてください。